一.Python基础语法
1.字面量
被写下来的固定不变的值(常量)。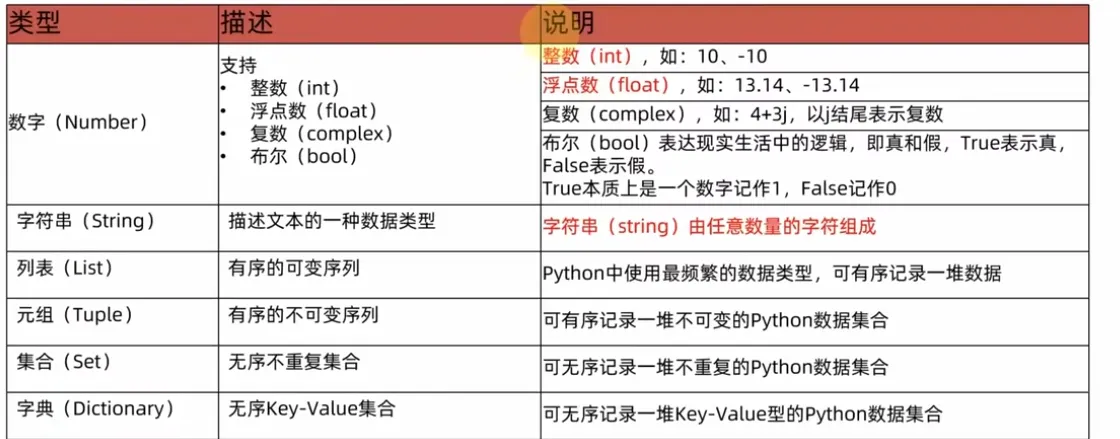
2.变量
在程序运行时,能储存计算结果或能表示值的抽象概念。
事实上,说“储存”是有所偏颇的,准确的来说,Python的变量实际上是对象的引用。(可以理解为C中的指针概念)
定义格式:
变量名称=变量的值
(见test01.py)
3.数据类型
- type语句:查看数据类型。
- 即使是查看的变量类型,也是数据类型,因为Python不同于C,它没有严格的类型检查,因此,它的变量是没有类型的,查看的变量的类型实际上是其中存储的数据的类型。
4.数据类型转换
- 为什么要转换类型?

- 常见的转换语句。
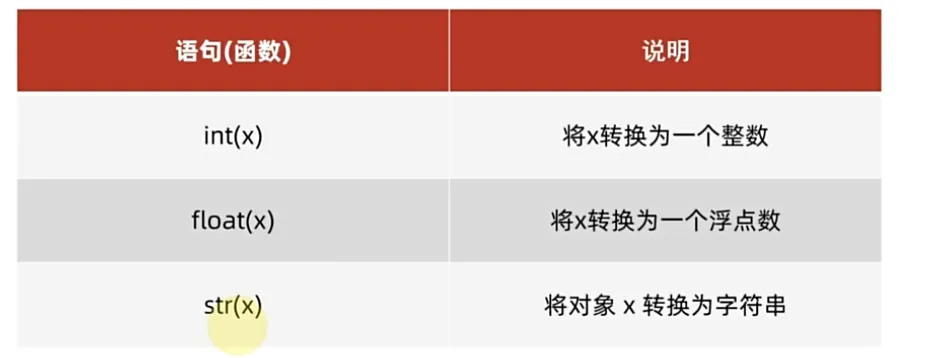
值得注意的是,这里的三个函数同type()一样都是带返回值的,可以直接在print函数中输出,或者将其存储于变量中。
- 浮点和整型都可以转字符串
- 字符串不一定能转浮点和整型
- 浮点转整型会丢失小数部分
5.标识符
标识符就是名字,给变量,方法,类等取的名字,用于做内容的标识。-
标识符的命名规则:
1.只允许出现英文,中文,数字,下划线。其中,中文不推荐使用,数字不能放开头。
2.Python大小写是敏感的。
3.不可使用关键字。
-
标识符的命名规范:
1.简洁明了
2.下划线命名法:
用下划线分隔单词,以免歧义
3.英文字母全部小写
6.运算符
- 算术运算符
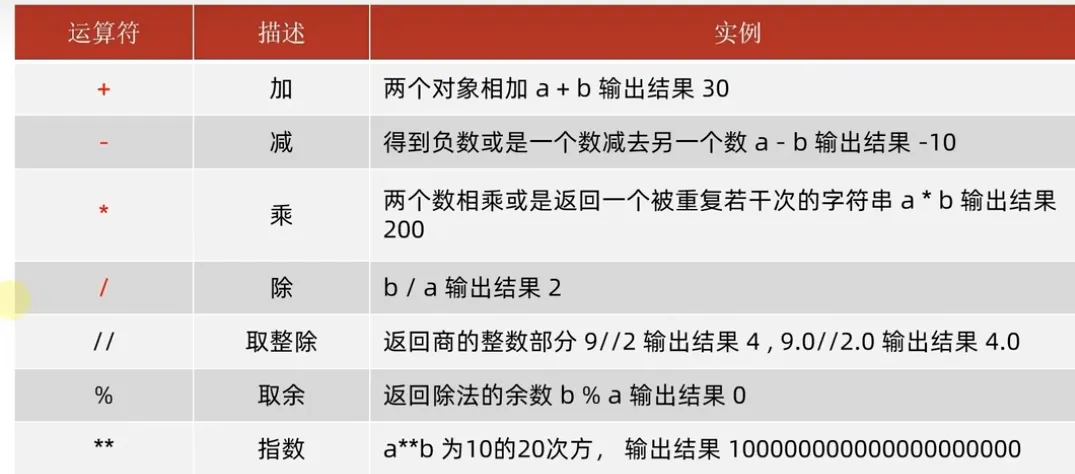
(这里需要注意的是,Python中的除法一定得到浮点型结果,且正常除法与整除是分别由一个运算符来运算的,不像C中是同一个运算符,结果由除数和被除数的类型决定。)
-
赋值运算符:
右赋左。
-
复合赋值运算符:
与C中一样由算数运算符+赋值运算符构成,功能也一样。
7.字符串扩展内容
1.字符串的三种定义方式:

- 字符串的引号嵌套

2.字符串的拼接

(值得注意的是,通过”+“号对字符串的拼接仅限于字符串类型,浮点和整型会报错。)
3.字符串格式化
- 占位符%,和C基本一样。

(当然,也可以使用%d,%f对整型和浮点型进行原封不动的输出,这里只用%s是因为进行了隐式转换。)
- 快速格式化字符
print(f"我是{name},年龄{age}")或者
print("My name is {} and I am {} years old".format(name, age))(不关心类型和精度控制。)
事实上格式化并不是变量的专属,常量和表达式仍然可以直接格式化输出。
4.格式化的精度控制

(注意:这里的四舍五入就是最常见的四舍五入,而不是C中的四舍六入五成双。)

(见test02.py)
8.数据输入
- input语句:从stdin获取输入数据。
- input函数有返回值,也就是说可以赋值进变量。
- input默认接收的数据都是字符串,输出其他类型需要强制转换。

(见test03.py)
二.Python判断语句
1.bool类型与比较运算符
- bool类型:与C中相同,略
变量名 = True/False- 比较运算符:同C
2.if语句的基本格式
if age >= 18:
print(f"this place isn't for you")
print("get out!")(与C不同,Python中判断一条语句是否从属于判断语句并不是用{}括起来进行分区,而是看是否有一个制表符的缩进。)

(见test04.py)
3.if……else语句
if age >= 18:
do1
do2
else:
do3
(见test05.py)
4.if……elif……else语句
if condition1:
do1
elif condition2:
do2
else:
do35.判断语句的嵌套
思想和C相同的,略
6.实操案例

(见test07.py)
三.Python循环语句
1.while基础语法
while condition:
do1
do2
do3
……(与C几乎一样,唯一需要注意的就是字符缩进)
2.while基础案例
(见test09.py)
3.while嵌套循环
同C,唯一要注意的是,多个循环嵌套及条件分支时,没有了{}的明显区分,需要格外注意缩进来正确分块。
4.while嵌套循环实操
补充:print输出不换行的写法
print("dfshjfs0",end='')
print("sdjgsgsd",end='') (见test10.py)
(见test10.py)
5.for循环基础语法
for 临时变量 in 数据集:
do(需要格外注意地是,Python中的for循环与C中的for循环的不同,C中的for循环可以等价写成while循环,但Python中无法定义循环条件)
理论上将Python中的for循环无法构建无限循环,因为不可能存在一个数据集中的元素个数无限。
临时变量x不一定要打印,也可以仅仅将其当作计数器使用。

(见test11.py)
6.range语句
for循环语法中的带处理数据集事实上应该叫做“序列”,是一种特殊的类型。
序列类型是指,其中的内容可以一个个依次取出的一种类型,包括:- 字符串
- 列表
- 元组
- ……
range(num)
#获取一个从0开始到num(不含num)的数字序列
range(num1, num2)
#获取一个从num1开始到num2(不含num2)的数字序列
range(num1, num2, step)
#获取一个从num1开始到num2(不含num2)的数字序列
#数字间的步长以step为准(step默认为1)
(见test12.py)
7.*变量作用域
- 同C
- 虽然在Python中可以尝试访问一个异域的变量,但是保不齐会出问题,尤其是在写大项目时。
- 如果真的想访问,可以先在大的域中定义一个变量名相同的变量,在for循环中对临时变量进行覆盖
8.for循环的嵌套循环
for x in range1:
do
for y in range2:
do
or
for ……:
do
while ……:
do
(见test13.py)
9.循环中断
- continue:中断本次循环,直接进入下一次循环。
for i in range:
do1
continue
do2
#上述代码不会执行do2(continue能且仅能中断离他最近的循环)
- break:直接结束循环
for i in range:
do1
break
do2
do3
#上述代码直接结束循环,do1后直接do3,不再进入循环(同样地,break也仅能跳过离他最近的循环)
10.综合案例

(见test14.py)
四.函数
函数,是**组织好**的,**可重复使用**的,用来实现特定功能的代码段。同样的,Python除了自身有庞大的函数库外,也支持自己定义函数。1.函数的定义
def function_name(parameter1, parameter2, ……):
function_struct
return ret调用:function_name(parameter1, parameter2, ……)即可。
2.*函数的参数
与C基本相同,唯一要注意的是在一些情况下,对函数的形参进行修改是会导致实参的改变的。
(见test15.py)
3.函数的返回值
与C基本相同,唯一要注意的是,无论有没有人为定义一个返回值,最终函数都会产生返回值,当没有人为定义的返回值时,此时返回值是“None”
**None**在Python中是一种类型'NoneType',代表“无,空的,无意义”。None的实际应用:
- 无函数返回值
- if条件判断:
def check_age(age):
if age > 18:
return "sucess"
return None
result = check_age(age)
if not result:
print("Forbid child to enter there!")- 声明无内容的变量:
a = None
#仅声明,不赋值4.函数的嵌套
在一个函数的里面再调用函数。5.*变量的作用域
-
变量分为两类:局部变量,全局变量。
-
局部变量是指在函数内部定义的变量,它的作用域和生存周期和函数相同,也就意味着无法在函数外对其进行访问。
-
全局变量,至少对于Python来说,是指定义在函数外的变量。作用域和生存周期和程序相同。
-
如何在使在函数内定义的局部变量的值能“映射”到函数外的相同变量名的变量?
1.golobal关键字
可以理解为强制将变量类型转化为全局变量。
2.引用特殊类型对象的变量
修改一个可变对象(如列表、字典等)作为函数的形参时,会改变 实参的值。
6.综合案例

(见test16.py)
五.Python数据容器
1.数据容器入门
一种可以容纳多份数据的**数据类型**,容纳的每一份数据称为一个元素,**每一个**元素可以是**任意类型**的数据,如字符串,bool……(类似于C中的结构体)。数据容器根据某些特征可以分为5类:
- 是否支持重复元素
- 是否可以修改
- 是否有序
列表(list),元组(tuple),字符串(str),集合(set),字典(dict)
2.数据容器:list(列表)
1.list(列表)的定义
#字面量列表
[element1,element2,……]
#变量列表
variable_name = [element1,element2,……]
#空列表:
variable_name = []
variable_name = list()注意:列表可以一次性存储多个数据,且可以为不同的数据类型
2.list(列表)的索引
类似于数组,不同的是,这里的元素下标可以从后往前定义,eg:list = [element1,element2,elemrnt3]
list[0] = element1
list[1] = elemrnt2
list[3] = element3
also
list[-1] = element3
list[-2] = element2
list[-3] = element1对于list的嵌套,可以像二维数组一样进行下标索引。
3.*list(列表)的方法与特点
1.方法
本质上就是函数,只不过当函数被定义为在[class]()(类)的成员,那么此时的函数就称之为方法。
函数和方法的参数,返回值,定义方式都一样,唯一值得注意的是,当我们调用一个class中的方法时与调用函数不太一样,eg:#定义
class Class_name:
def method(param):
do
#调用方法
variable = Class_name.method(param)那么对于列表(list)来说,它是由Python内置的list类实现的。也就是说,列表是一个list类的实例。2.list列表的常用操作
#定义列表
mylist = [elem1, elem2, elem3]- 查找某元素在列表的下标索引
#语法:list.index(elem)
number = mylist.index(elem1)
print(number) #结果输出elem1的下标
print(mylist.index(elem))
#结果为:ValueError- 修改特定下标索引值
#本质就是赋值操作
mylist[0] = element- 插入元素
#语法:list.insert(index, elem)
mylist.insert(1, elem)
#结果:[elem1, elem, elem2, elem3]- 追加元素
- 单个追加
#语法:list.append(elem)
mylist.append(elem)
#结果:[elem1, elem2, elem3, elem]- 批量追加
#语法:list.extend(another data container)
mylist.extend([elem4, elem5, elem6])
#结果:mylist = [elem1,elem2,elem3,elem4,elem5,elem6]注意:list.extend()接受任何可迭代对象(iterable),也就是说,这里的其他数据容器不仅仅指list。- 删除指定下标索引的元素
#语法1:del list[index]
del mylist[2]
#结果为:mylist = [elem1,elem2]
或者
#语法2:list.pop(index)
name = mylist.pop(2)
#结果为:mylist = [elem1,elem2]注意:list.pop(index)方法有返回值,本质上它是将下标为index的值“取出”作为返回值,同时,list里下标为 index的值被删除。- 删除指定元素在list中从前向后数的第一个匹配项
#语法:list.remove(elem)
list.remove(elem1)
#结果为:mylist = [elem2,elem3]- 清空列表内容
#语法:list.clear()
mylist.clear()
#结果:mylist = []- 统计某元素在列表中的数量
#语法:list.count(elem)
print(mylist.conut(elem1))
#结果为:1- 统计列表中全部元素的数量
#语法:len(list)
print(len(mylist))
#结果为3注意:这里的len不是方法,是函数。3.列表的遍历
对一个数据结构中的每一个元素进行访问和操作称之为遍历或迭代
尽管同样是对数据结构每一个元素的访问,但是遍历强调的是访问数据结构中每一个元素的**过程**,而迭代则更强调实现这个过程的**代码段的重复**过程,因此我们可以说遍历**通常**可以通过迭代实现。
(见test18.py)
4.数据容器:元组(tuple)
1.元组(tuple)的定义
元组同列表一样可以封装多个,不同类型的元素在内。但是它们最大的不同点在于元组一旦定义完成就**无法修改**#定义元组字面量
(elem1,elem2,elem3)
#定义元组变量
variable_name = (elem1,elem2,elem3)
#定义空元组
variable_name = ()
或者
variable_name = tuple()需要强调的是,当定义元组时,元组元素只有一个时,元素后须接逗号。 variable_name = (elem,)2.元组(tuple)的下标索引
与列表相同,不过多赘述。
但是值得注意的是,在 Python 中,无论是列表、元组还是字符串,都使用方括号`[]` 来索引或切片。这是一个通用的规则,适用于所有序列类型的数据。3.元组(tuple)的常用操作
#定义列表
mytuple = [elem1, elem2, elem3]- 查找某个元素的下标
#语法:tuple.index(elem)
number = mytuple.index(elem1)
print(number) #结果输出elem1的下标
print(mytuple.index(elem))
#结果为:ValueError- 统计某元素在元组中的数量
#语法:tuple.count(elem)
print(mytuple.conut(elem1))
#结果为:1- 统计元组内元素个数
#语法:len(tuple)
print(len(mytuple))
#结果为34.元组的读写性
元组本身没有写的权限,但是元组中嵌套的可变数据结构中的元素是可以修改的。
(见test19.py)
5.数据容器:字符串(str)
1.字符串的定义
字符串是只含有字符类型的数据容器,它与元组一样不可修改。2.字符串的常用操作
#定义字符串
mystr = "fsudygfusgf"- 查询元素下标
#语法:str.index(elem)
print(mystr.index('f'))
#结果为0- 字符串的替换
#语法:str.replace(str1,str2)
print(mystr.replace('f','a'))
#结果为"fsudygfusgf"
print(mystr)
#结果为"asudygfusgf"注意:这里并不是将mystr中的值给覆盖了再输出mystr,而是相当于一个返回值。
- 字符串的分割
#语法:str.split(分隔符字符串)
mystr = "hello world"
print(mystr.split(" "))
#结果为:['hello', 'world']正如上面的结果所示,mystr.split()也不是对mystr进行分割,而是根据分割字符串将分割的结果以列表的形式返回。
- 字符串的规整操作
#去前后空格
mtstr = " hello world "
print(mystr.strip())
#结果为:"hello world"
#去前后指定字符串
mystr = "12hello world21"
print(mystr.strip("12"))
#结果为:"hello world"同样的,mystr.strip也不会更改mystr的值,也是将新字符串作为返回值返回。
- 统计某字符串出现的次数
#语法:str.count(string)
mystr = "hello world"
print(mystr.count("l"))
#结果为:3- 统计字符串长度
mystr = "hello world"
print(len(mystr))
#结果为:11值得特别注意的是,Python中的字符串并不以’\0’结尾。

(见test20.py)
6.数据容器(序列)的切片
- 序列:内容连续,有序,可使用下标索引的一类数据容器。元组,列表,字符串都是序列的一种。
- 序列的切片:从一个序列中取出一个子序列
#语法:sequence[start_subscript:end_subscript:step]
#表示从序列中,指定位置开始,依次取出元素,到指定位置结束,得到一个新序列- 起始下标表示从何处开始
- 结束下标(不含)表示何处结束,可以留空,留空视作取到结尾
- 步长表示依次取元素的间隔
- 步长n表示,每次跳过n-1个元素取
- 当n<0时,表示反向取(此时,起始下标和结束下标也要反向标记 )
- 步长为n(n<0),每次反向跳过n-1个元素取
- 切片操作并不会更改原有序列,而是会产生新的序列

(见test21.py)
7.数据容器:集合(set)
1.集合的定义
#定义集合字面量
{elem1,elem2,elem3}
#定义集合变量
set_name = {elem1,elem2,elem3}
#定义空集合
set_name = set()之所以这里只能使用set()而不是set{}的原因是,set是python的内置函数,用于创建集合对象,eg:
mylist = [1,2,3,4]
myset = set(mylist)
#myset = {1,2,3,4}可以通过set函数创建空集合或者从其他可迭代数据结构中获取元素来创建集合。
2.集合的常用操作
#定义一个集合
myset = {elem1, elem2, elem3}- 添加新元素
#语法:set.add(elem)
myset.add(elem)
print(myset)
#结果:myset = {elem1,elem2,elem3,elem}
myset.add(elem1)
print(myset)
#结果为:myset = {elem1, elem2, elem3}注意:set集合不支持重复元素。
- 移除元素
#语法:set.remove(elem)
myset.remove(elem1)
print(myset)
#结果:myset = {elem2, elem3}- 随机取出一个元素
#语法:set.pop()
myset.pop()
print()
#结果:不定,因为集合没有下标,所以pop会随机取出一个元素,并把这个元素作为返回值返回- 清空集合
#语法:set.clear()
myset.clear()
print(myset)
#结果:set()- 取两个集合的差值
#语法:set1.difference(set2)
set1 = {1,2,3}
set2 = {1,4}
set3 = set1.difference(set2)
print(set3)
#结果:set3 = {2,3}注意:difference方法会创建一个新的集合作为返回值返回,而不是修改set1或set2。并且,新集合的元素是set1有而set2没有的元素。
- 消除两个集合的差值
#语法:set1.difference_updata(set2)
set1 = {1,2,3}
set2 = {1,4}
set1.difference_updata(set2)
print(set1) #结果为:{2,3}
print(set2) #结果为:{1,4}注意:difference_updata方法直接在set1上修改,删除set1中与set2中相同的元素,而不修改set2。
- 合并两个集合
#语法:set1.union(set2)
set1 = {1,2,3}
set2 = {1,4}
set3 = set1.union(set2)
print(set3) #{1,2,3,4}
print(set2) #{1,4}
print(set1) #{1,2,3}注意:union方法不会修改set1和set2的值,而是合并集合后创建一个新的集合,并将新集合作为返回值返回。
- 统计元素个数
len(set)-
集合的遍历
不支持while循环,因为没有下标。但是支持for循环。

(见test22.py)
8.数据容器:dict(字典)
1.dict(字典)的定义
#定义字典字面量
{key1:value1,key2:value2,key3:value3}
#定义字典变量
mydict = {key1:value1,key2:value2,key3:value3}
#定义空字典
mydict = {}
或
mydict = dict()- 键值对,像key:value这样可以将关键信息与值匹配起来称为一个元素的称之为键值对。
- 重复定义字典:
mydict = {key1:value1,key1:value2,key3:value3}
print(mydict)
#结果:mydict = {key1:value2,key3:value3}注意:重复定义字典(即key值相同),后定义的键值对会将先定义的键值对
覆盖。
- 字典数据的获取
mydict = {key1:value1,key1:value2,key3:value3}
print(mydict[key1])
print(mydict[key2])
print(mydict[key3])注:字典没有下标,但是可以通过key取到value。
-
嵌套字典 字典的key和value类型不受限制(key不能为字典),这就意味着字典可以嵌套。
-
嵌套字典的索引
类似二维数组的索引
dict[key_surface][key_inner]2.字典的常用操作
- 新增元素和更改元素
#在字典中我们可以对键值对中的value进行修改,eg:
dict[key] = value_new
#当key不存在时就是新增了一个键值对
#当key存在时就是对键值对key:value的value进行了修改,相当于更新元素- 删除元素
#语法:dict.pop(key)
mydict = {key1:value1,key2:value2,key3:value3}
print(mydict.pop(key1))
#结果为:value2
print(mydict)
#结果为:mydict = {key1:value2,key3:value3}注意:pop(key)方法可以取到键值对key:value的value,并且将该键值对从字典中删除。
- 清除字典
#语法:dict.clear()
mydict.clear()
#结果为:{}- 获取全部key和遍历字典
#语法:dict.keys()
keys= = mydict.keys()
print(keys)
#结果:mydict = {key1,key2,key3}获取key之后就可以进行遍历了
for key in keys:
或者
for key in mydict:注:上述两者的key值是完全等价的
- 统计字典中的元素数量
len(mydict)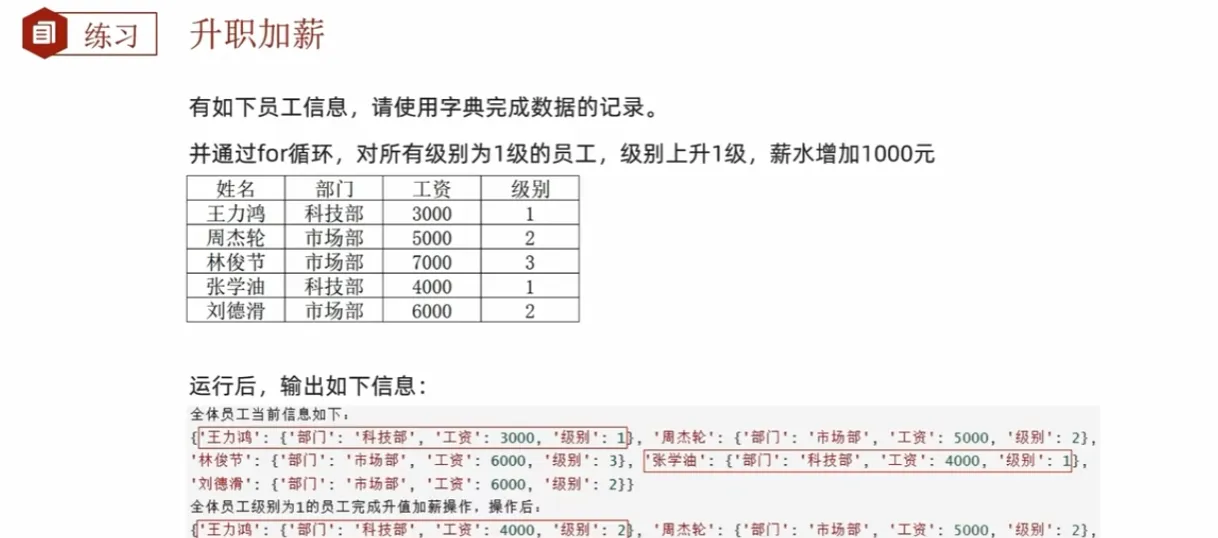
(见test23.py)
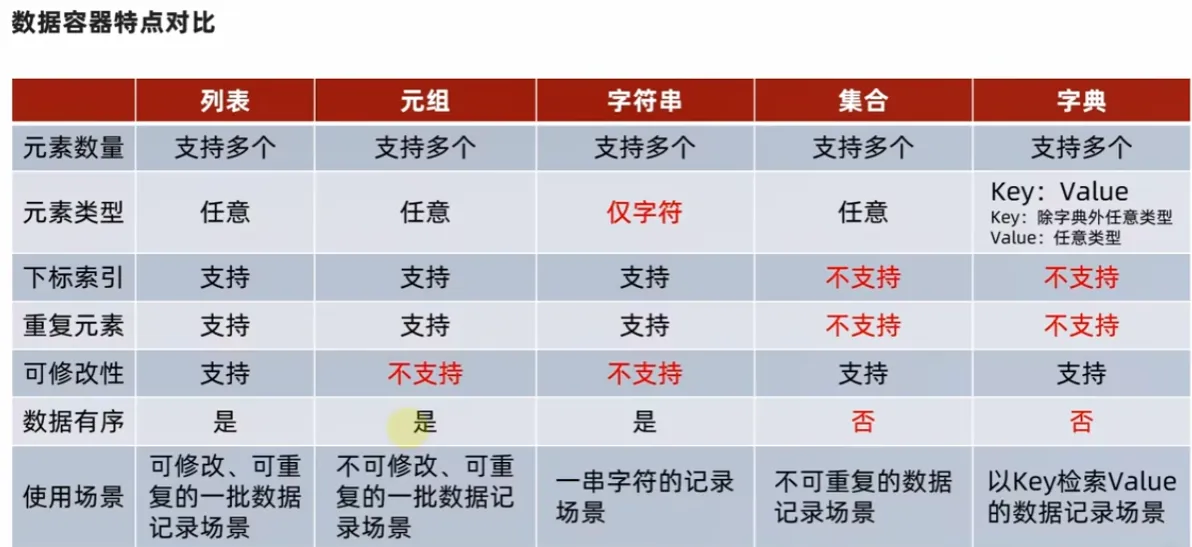
9.数据容器总结
-
是否支持下标索引:
- 支持:列表,元组,字符串---序列类型
- 不支持:集合,字典---非序列类型
-
是否支持重复元素:
- 支持:列表,元组,字符串---序列类型
- 不支持:集合,字典---非序列类型
-
是否可以修改:
- 支持:列表,集合,字典
- 元组,字符串
10.数据容器的通用操作
-
都支持遍历操作
- 序列支持while
- 非序列不支持while
-
通用方法:
- len() (计算元素个数)
- max() (取最大元素)
- min() (取最小元素)
- 字符串也支持ASCII码
-
强制转换:
- list(data_container)
- str(data_container)
- tuple(data_container)
- set(data_container)
-
通用排序函数:
sorted(data_container, [reverse=True])
[reverse]默认是False,如果想让排序反转,[reverse=Ture]
六.函数进阶
- 函数的多返回值:
def function(param):
return ret1, ret2
a, b = function
print(a) #ret1
print(b) #ret2- 函数的多种传参方式:
-
位置参数:
- 通过位置传递参数,参数的值根据其位置来匹配。
def func(a, b): return a + b result = func(1, 2) # a=1, b=2 -
关键字参数:
- 使用关键字(参数名)传递参数,可以不按顺序传递。
result = func(b=2, a=1) # a=1, b=2 -
默认参数:
- 在定义函数时为参数设置默认值,如果调用时不传递该参数,则使用默认值。
def func(a, b=2): return a + b result1 = func(1) # b使用默认值2 result2 = func(1, 3) # b=3 -
可变位置参数(*args):
- 使用星号(
*)可以接收任意数量的位置参数,这些参数会被存储在一个元组中。
def func(*args): return sum(args) result = func(1, 2, 3, 4) # args=(1, 2, 3, 4) - 使用星号(
-
**可变关键字参数(kwargs):
- 使用双星号(
**)可以接收任意数量的关键字参数,这些参数会被存储在一个字典中。
def func(**kwargs): return kwargs result = func(a=1, b=2) # kwargs={'a': 1, 'b': 2} - 使用双星号(
-
命名关键字参数:
- 在函数定义中可以限制关键字参数的名称,使用
*来分隔位置参数与命名关键字参数。
def func(a, b, *, c, d): return a + b + c + d result = func(1, 2, c=3, d=4) # c=3, d=4 - 在函数定义中可以限制关键字参数的名称,使用
-
参数类型提示:
- 使用类型提示来指明参数的预期类型,增加代码的可读性和可维护性。
def func(a: int, b: float) -> float: return a + b
这些方法各自有其使用场景,可以根据需要选择适合的传参方式。
- **匿名函数
- def 可以定义一个带有名称的函数,lambda可以定义一个匿名函数
- 有名称的函数可以基于名称重复调用,匿名函数仅作临时使用
#定义语法
lambda (parameter1,……):function_struct
#值得注意的是,函数体中仅能写一行代码
#实操
def test_func(com):
ret = com(1, 2)
return ret
print(test_func(lambda x,y: x*y))
#结果为:2
#等价于:
def add(x, y):
return x+y
def test_func(add):
ret = add(1, 2)
return ret
print(test_func(add))七.Pyhton文件操作
1.文件编码
编码技术:翻译的规则,记录了如何将内容翻译为二进制机器语言,以及如何将二进制文本转换为可识别内容。
但是编码的规则多种多样,但是现在一般都使用UTF-8编码规则。2.文件的读取
-
文件操作的作用
内存中存放的数据在计算机关机后就会被重置,也就是说要长久地保存文件就得使用硬盘,光盘,U盘等设备。
但是很显然地,如果仅仅是这样,对于保存数据地再访问是麻烦的事。于是,引入“文件”的概念,方便数据的管理与检索。
一般来说,一段音频,一段视频,一个可执行程序都可以被保存为一个文件,并赋予一个文件名。操作系统以文件为单位管理磁盘中存储的数据。
文件一般可以分为文本文件,视频文件,音频文件,图像文件,可执行文件等多种类别。
在日常生活中,文件的操作主要包括打开,关闭,读,写等操作。
-
文件的读取
- open()打开函数
#语法:open(name,mode,encoding) #name:是要打开的目标文件名的字符串(可以包含文件所在的具体路径)。 #mode:设置打开文件的模式(访问模式):只读、写入、追加等。 #encoding:编码格式(推荐使用UTF-8) f = open('python.txt', 'r', encoding=" UTF-8) #encoding的顺序不是第三位,所以不能用位置参数,用关键字参数直接指定注意:此时的’f’不是变量,而是open函数的文件对象。
mode常用的三种基础访问模式:

-
读操作相关方法
当open了一个文件对象’f’后,这个文件对象中会内置很多方法
- read()方法
f.read(num) #num表示要从文件中读取的数据长度(以字节为单位),如果没有传入num,那么就代表读取文件中的所有数据。- readlines()方法:
f.readlines() #readlines()方法按照的方式把整个文件中的内容进行一次性读取,并且返回的是一个列表,其中每一行的数据为一个元素。- readline()方法:
f.readline() #readline方法每次只读取一行数据,返回内容是字符串- for循环读取文件行
for line in open(file_name) print(line) #每一个line临时变量就记录文件的一行数据- close()方法关闭文件对象
f = open(file_name) f.close #通过close关闭文件对象,也就是关闭对文件的占用 #如果不调用close,且程序一直运行,则该文件将一直被Python占用。- with open函数
with open(file_name,mode) as f: f.method() #该函数可以在操作完毕后自动关闭文件,以防忘记使用close。

(见test24.py)
3.文件的写入
f = open(file_name,'w')- write()方法:
f.write(写入的内容)
#仅仅write方法还并不能将内容写入文件,而是会积攒在程序的内存中,称之为缓冲区。
#这是为了避免频繁操作硬盘,导致效率下降- flush()方法:
f.flush()
#内容刷新,将缓冲区内的数据刷新至文件。4.文件的追加
f = open(file_name,'a')- write()方法:
f.write(追加的内容)
#仅仅write方法还并不能将内容追加至文件,而是会积攒在程序的内存中,称之为缓冲区。
#这是为了避免频繁操作硬盘,导致效率下降- flush()方法:
f.flush()
#内容刷新,将缓冲区内的数据刷新至文件。八.Python异常,模块与包
1.了解异常
异常是检测到错误时,Python解释器无法继续运行,即为异常,可能是语法错误,如用lambda定义有名称函数,也有可能是逻辑错误,如下标索引超出范围。2.异常的捕获方式
捕获异常的意义在于提前假设某处会出现异常,提前做好准备,当真的出现异常时可以有后续的手段,以此增强程序的健壮性。- 捕获常规异常
#基本语法:
try:
可能发生错误的代码
except:
如果出现异常执行的代码- 捕获指定异常
#基本语法:
try:
可能导致异常的代码
except SpecialError as e:
如果出现特定异常,执行的代码
#在python中本身内置了很多种类的异常,as e的意思是将这个异常信息赋值给变量e
- 捕获多个异常
#基本语法:
try:
可能导致异常的代码
except (SpecialError1,SpecialError2) as e:
如果出现特定异常,执行的代码
#注意:这里是满足任意一个异常就会被被捕获,并将异常信息赋值给变量e- 捕获全部异常
#基本语法:
try:
可能导致异常的代码
except Exception as e:
如果出现特定异常,执行的代码- 异常的else和finally语法
- 异常的else:
#基本语法:
try:
可能导致异常的代码
except (SpecialError1,SpecialError2) as e:
如果出现特定异常,执行的代码
else:
stuct也就是说,如果没有异常就会执行else里的语句,同时try中的语句也会执行- finally:
#基本语法:
try:
可能导致异常的代码
except (SpecialError1,SpecialError2) as e:
如果出现特定异常,执行的代码
else:
stuct
finally:
dofinally的作用在于不管如何都会执行finally中的语句。- 异常捕获需要注意的点:
- try中的语句如果任意一条触发异常,那么整个try中的语句都不会执行
- 常规捕获的是指捕获任何会造成程序中断的异常,包括系统退出、键盘中断等不属于程序本身的部分,但是全部捕获是指捕获在Exception这个类及其子类的异常
3.异常的传递
异常是可以传递的。异常会一直传递到执行的最高层级.
也就是说,即使异常存在的结构中没有捕获手段,程序并不会直接报错,而是继续向高层级查找是否会有一个存在于其他结构中的捕获代码对这个异常进行调用,如果没有则报错
显然地,我们如果想要处理异常并不需要真正到异常出现的那个语句中去。#例如:
def a():
func = 1/0
return func
def main():
try:
print(a())
except:
print("Error")4.python的模块
python模块(Module),是一个python文件,以.py结尾。模块能定义函数,类和变量,也包含可执行的代码。
模块的作用在于帮助我们**快速实现一些功能**,而不用自己写脚本。我们可以认为:
**模块==工具包**
**里面的函数,类和变量==工具**- 模块的导入
#语法
[from Moudule_name] import[Module|class|variable|function|*] [as alias]
#*表示导入模块内的全部内容
#[]在python代码描述语句中表示可选择的内容自定义模块
尽管python中有许多内置的模块,但是总不可能所有的场景都适用,于是自定义模块就很重要。
前文说到,模块本质上就是.py文件,那么自定义模块就是建立一个自己的.py文件,需要用时,引用文件名即可,自定义模块的引用与内置模块的引用方式并无差别。
调用时需要注意的小细节:当调用了不模块的同名内容,后调用的会覆盖先调用的。(事实上,pycharm的提示信息会将没有使用的函数,变量,模块标灰)- 测试模块
#不妨我们可以设置一个简单的自定义模块如下:
def add(x,y):
print(x+y)
add(1,2)
#对模块功能进行测试当我们写好模块之后难免会对功能进行测试,但是导入模块时会先对模块进行运行,这样一来测试的代码就会被执行,如果不想测试代码被执行呢?
**内置变量\_\_name\_\_**:
python中存在值固定的内置函数,比如\__name__,\_\_name\_\_变量表示当前.py文件在执行的过程中的”地位“,如果当前文件是主函数,那么\_\_name\_\_的值为\_\_main\_\_,如果作为模块,那么\_\_name\_\_的值为模块名。
于是,可以使用如下代码来进行模块检测,同时检测代码不会在导入时被运行。def add(x,y):
print(x+y)
if __name__ == "__main__":
add(1,2)- __all__变量:
from Moudule import *
#这个*说是全部内容,事实上是定义在__all__变量中的所有内容
#那么当我们通过重新定义__all__变量就可以将一些其他无关内容排除在外5.安装第三方包
包是模块的集合,安装第三方包只需要通过pip即可安装。但是pip默认是从国外的网站下面下载的,想提高效率可以用国内的镜像站。
或者通过pycharm下载。